I got a bipartite graph of user(~300K)-item(~300K) ratings :
| :START_ID(User) | :END_ID(Item) | rating:INT |
|---|---|---|
| 1234 | 8765 | 1 |
| 66 | 88 | 5 |
| … | … | … |
which can be represent as a csr matrix of real number R and it’s boolean version B & C.
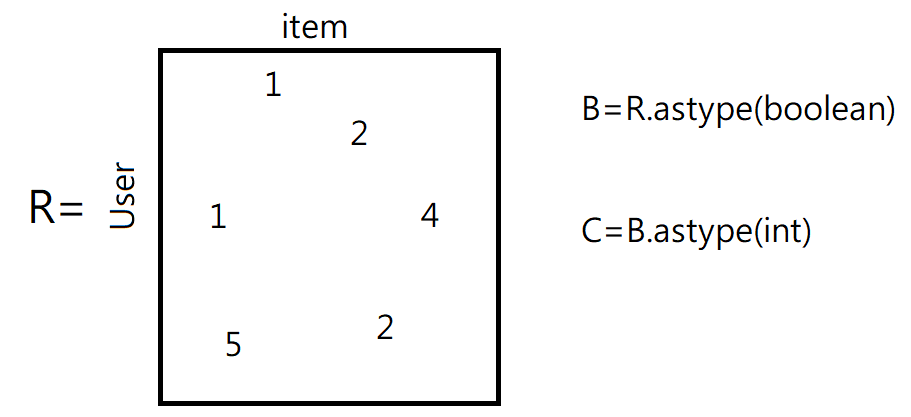
And I try to get items similar to a specific item by querying
MATCH (:Item {id: 6})<-[:RATE]-(u:User)-[:RATE]->(i:Item)
RETURN i.id, count(u) AS similarity
// referece
// stackoverflow.com/questions/29066274/count-duplicated
gives the same answer as ![]() . (but is it done like this?)
. (but is it done like this?)
Q1:
How about ![]() or
or ![]() ?
?
How to apply matrix multiplication (float) with more explicit query?
Just like ![]()
MATCH (o:Item {id: 6})<-[]-(:User)-[]->(:Item)<-[]-(:User)-[]->(i:Item)
RETURN o, i // [,count(*)]
// referece
// www.slideshare.net/RedisLabs/redisconf18-lower-latency-graph-queries-in-cypher-with-redis-graph
does the chain matrix multiplication of boolean matrices . ![]()
Q2:
I expect following query was done by ![]() , where
, where R' is R with case when replacement.
But query is slow when the item is rated by many user, and all GRAPH.EXPLAIN can tell me is “aggregate”.
MATCH (:Item {id: 6})<-[:RATE]-(:User)-[r:RATE]->(i:Item)
RETURN
i.id,
SUM(CASE r.rating
WHEN 1 THEN 2
...
END)
and another try
MATCH (:Item {id: 6})<-[:RATE]-(us:User)
WITH distinct(us) as u, count(*) as cnt
MATCH (u)-[r:RATE]->(i:Item)
RETURN
i.id,
SUM(cnt*
(CASE r.rating
...
END)
)